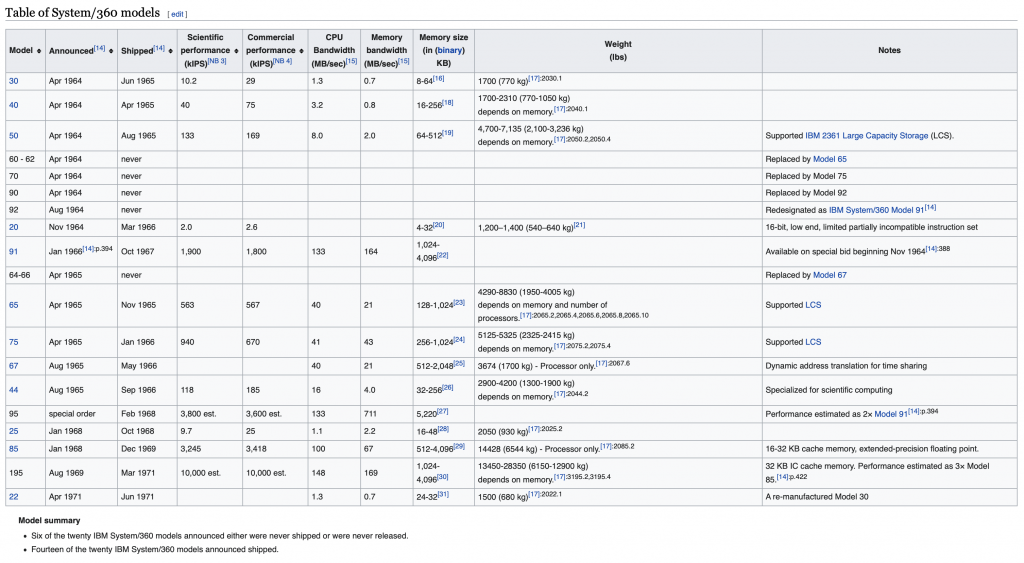
影响软件度量的事件中,比较有影响力的是 1964 年由 Gene Myron Amdahl 担当架构师(也就是阿姆达尔定律的提出者),由 Frederick P. Brooks, Jr. 担当项目经理的 IBM System/360。为了开发这台电脑,IBM 新招了 6 万名员工,还新开了 5 座工厂;其项目也是雄心勃勃的——他们要藉 OS/360 一统 IBM 的系列产品,告别按电脑型号定制操作系统的旧时代。
One model from IBM System/360 family, retrieved from https://matt.blog/2013/03/08/an-ibm-system-360/IBM System/360 Models, retrieved from https://en.wikipedia.org/wiki/IBM_System/360
作为蓝色巨人倾国之力打造的里程碑式的作品,OS/360 的血脉流淌在 IBM 此后的每一个大型系统中;而自然,其代价也是昂贵的——这毕竟是人类历史上少有的大型项目,其中遇到的技术之外的困难是众多、难解却弥足珍贵的。Frederick P. Brooks, Jr. 把开发 System/360 和 OS/360 的历程、阻碍和思考在1975年写成了一本书:《The Mythical Man-Month: Essays on Software Engineering》,中文译本标题比较草,叫《人月神话:软件项目管理之道》——“人月”指的是“一个人要花几个月才能开发完一个系统的功能单位”,这是当时衡量软件工时的一个潮流;而神话这个词翻译得就不好了,因为 Mythical 指的是 “迷惑性且不可实现的”。书中的第二部分,便是阐明了人数和必要工时间的非线性关系,指明了人月标准的错误。这和书中的诸多思想一起,成为了对软件工程和软件度量的重要探索基础。
关于软件度量的成文专论,要晚在 1976 年才出版;因为最早的软件度量,是机械地度量行数,看起来没什么必要去写什么专论。有同学可能就要问了,为什么是量行数?你看我 10 行就能解个八皇后问题,遇到不会写 for 循环搞出一万行代码的人我不是亏了嘛;答案很简单——那时的代码可不是我们这种高级语言,都是些指令长度固定、指令集简单、甚至不需要编译器执行、再甚至要打在卡片上的代码。一行代码几乎严格地表示一个操作,也没有什么 attribute 之类的 “标记”,数行数也不是一个大问题;但是后来程序可以用更精简、非面条式的语句执行复杂的结构,单纯地数行数也就没有用了。于是从第一个新概念 “逻辑行数 (Logical Line of Code, LLOC)”对立于“物理行数 (Physical Line of Code)” 开始,人们对软件度量的技术,即“量化能力”提出了新的要求。
根据 Norman F. Schneiderwind 的描述,立体的软件度量包括六个方面:Association、Consistency、Discriminative Power、Tracking、Predictability 和 Repeatability,以 Non-parametric Statistical Method 衡量之。软件度量的五条路径分别是:Function Points、Reliability Reports by Programmers、Halstead Operator Count(For PASCAL)、Metric-based Classification Trees 和 Evaluation of Metrics against Syntactic Complexity Properties。时至今日,很多公司在说的 6-Sigma 以致 CMMI 也是软件度量涉及的东西。
From the Automata Theory before we moved to Computability Theory and Computational Complexity Theory, we had gone through several Formal Languages, Formal Grammars and Abstract Machines. For the lecture of COS487/MAT407 in Princeton, Formal System was the next topic for students’ discussion; but as long as I’m writing these posts in a line for everyone has the same amateur knowledge basis like me, I’d like to put the First-Order-Logic a bit off, and continue to explaining the Computability Theory in advance.
Speaking of those Abstract Machines, we can see the limitations each one of them easily: Due to the absence of storage, a Finite State Machine (FSM) can’t deal with those problems with ‘counting infinitely’ (eg., determine if a string ‘balanced’ with a and b, or \(L = \{a^n b^n | n ≥ 0 \}\)); a Pushdown Automaton (PDA) has infinite storage, but that storage is still a stack. That means a PDA must consume the input characters ‘in the order’ in which they are received, and cannot access them again, except by placing them on the stack. Therefore, a PDA can’t determine if a string satisfies such rules like ‘a string has the same amount of particular symbols in total’ (eg. “aacbcbdd”); besides, it only works on Context-Free…
Until we got A Turing machine – it has unlimited storage can be visited so efficiently under any order, any loop, any condition and any sub-function. Life is great ;D
Until, we reached the boundary of it. We added more features to those Turing machines but didn’t expand any additional abilities to them, by proving that those features can be replaced by another (bunch of) designed Turing Machines, if those features are applicable. Then where is that limitation of a Turing Machine? Is there an impossible program?
Those ‘General Systems’ such as Turing Machines are dealing with algorithms, not to mention computers. Then, to answer those questions, we have to see the features of an Algorithm. If we know the algorithms’ features and abilities, we might figure out what those limitations are.
In a total rudimentary way to explain, an algorithm is a set of instructions, each instruction takes an/ε input(s) and got an output of it/them. But there are 4 rules applied:
The number of instructions are finite;
The instructions can’t be complex;
The whole process with instructions can be done in finite length of time, if those instructions are followed/used correctly;
The result out of those sets of instructions must be ‘correct’ if those instructions are followed/used correctly.
Based on the 4 rules above, we can turn numerous algorithms into programming codes. But is it possible to convert each and every algorithm into a set of instructions for general systems’ execution? People (especially people writing codes) may just answer ‘yes’, following their instincts. Yet under the realm of Computational Architecture, the direct, abstractive idea of an algorithm is totally unequal to its logical, concrete implementation.
So again, can we design an algorithm with such unbelievable complexity and unmeasurable scale that no machine can grasp its stem?
Since 1930s, computer scientists have been working on creating an algorithm which could not be ‘solved’ by an abstract machine – every attempt of creating an model of computation returns a system, and those systems were all proved to have the equivalent capacity of a Turing machine, whereas there’s still no mathematical / logical proof for that general question. In fact, from the place I put up the 4 rules for algorithm, we are not be able to talk about the whole question on the level of logic or mathematics any more. But at least, along the way of exploration, we are confident to accept the hypothesis below:
“Every algorithm has the features as I mentioned in this post, can be executed by an abstract machine, or specifically, a Turing machine.” or let’s say, “a function on the natural numbers can be calculated by an effective method if and only if it is computable by a Turing machine.”
And here we reached the first stop of the Computability Theory: Church-Turing Thesis,
“We shall use the expression ‘computable function’ to mean a function calculable by a machine, and let ‘effectively calculable’ refer to the intuitive idea without particular identification with any one of these definitions.”
Turing, Alan (1938). Systems of Logic based on Ordinals (PhD thesis). Princeton University. doi: 10.1112/plms/s2-45.1.161.
or in Gandy’s(1980:123) words, every effectively calculable function is a computable function.
Despite of the form of Church-Turing Thesis is a ‘thesis’, a literature statement than a logical, formal expression, the Church-Turing Thesis came out from solid formalisms: the λ-calculus, besides recursion, and the Turing machine. Those are the topics up next, which requires we write something to show the power of those 3.
' n queens cast by go basic
[loop]
input "How many queens (N>=4)";n
if n < 4 then
print "Must be greater than 4"
goto [loop]
end if
dim plot$(100,100)
dim q(n+20)
dim e(n+20)
dim o(n+20)
r=n mod 6
if r<>2 and r<>3 then
gosub [samp]
goto [shoBoard]
end if
for i=1 to int(n/2)
e(i) = 2 * i
next
for i=1 to int((n/2)+.5)
o(i) = 2 *i-1
next
if r = 2 then gosub [edt2]
if r = 3 then gosub [edt3]
s = 1
for i=1 to n
if e(i)>0 then
q(s) = e(i)
s = s+1
end if
next
for i=1 to n
if o(i) > 0 then
q(s) = o(i)
s = s + 1
end if
next
' print board
[shoBoard]
cls
for i = 1 to n
plot$(i,26-q(i)) = "*"
plot$(i,24-n) = chr$(96+i)
plot$(n+1,26-i) = str$(i)
next i
for ii = 1 to 100
for jj = 1 to 100
print left$(plot$(jj,ii)+" ",1);
next jj
print
next ii
end
' the simple case
[samp]
p = 1
for i = 1 to n
if i mod 2=0 then
q(p) = i
p = p + 1
end if
next i
for i = 1 to n
if i mod 2 then
q(p) = i
p = p + 1
end if
next
return
' edit list when remainder is 2
[edt2]
for i=1 to n
if o(i) = 3 then
o(i) = 1
else
if o(i)=1 then o(i) = 3
end if
if o(i) = 5 then
o(i)= o(i) -1
else
if o(i) = 0 then
o(i) = 5
return
end if
end if
next
' edit list when remainder is 3
[edt3]
for i = 1 to n
if e(i) = 2 then
e(i) = e(i)-1
else
if e(i) = 0 then
e(i) = 2
goto [more]
end if
end if
next i
' edit list some more
[more]
for i = 1 to n
if (o(i)=1 or o(i)=3) then
o(i) = o(i)-1
else
if o(i) = 0 then
o(i) = 1
o(i+1) = 3
return
end if
end if
next
或是这样的尝试——
# Brute force permutations for 8 queens by R
safe <- function(p) {
n <- length(p)
for (i in seq(1, n - 1)) {
for (j in seq(i + 1, n)) {
if (abs(p[j] - p[i]) == abs(j - i)) return(F)
}
}
return(T)
}
queens <- function(n) {
p <- 1:n
k <- 0
while (!is.null(p)) {
if(safe(p)) {
cat(p, "\n")
k <- k + 1
}
p <- next.perm(p)
}
return(k)
}
queens(8)







 (八皇后问题的其中一个解)
(八皇后问题的其中一个解)